Intro
The merits of Infrastructure-as-Code (IaC) and GitOps are well understood in the industry, but when we started our IaC journey about a year ago, we couldn’t find any great online references about how it all should come together. Specifically, we were unsure how to accomplish controlled and safe promotions of changes across environments while adhering to GitOps guidelines. We now believe we have found a solution. I’ll go over how we structure our Terraform code and how its CI/CD pipelines work and try to explain the reasoning behind some of the choices we made.
I assume familiarity with Terraform, Github, and modern Software as a service (SaaS) development practices.
First, I need to say a few words about our tech organization. We have about 50 software developers in six development teams and five site reliability engineers (SREs), and all the teams use Terraform to manage cloud resources.
Our Terraform codebase manages a few thousand distinct cloud resources in AWS, GCP, Cloudflare, Mongo Atlas, and Datadog. Most of those resources have clear service ownership and are deployed in both Sandbox and Production environments, and there’s an assumption that changes in code and infrastructure happen in Sandbox before Production.
The Flow
Let’s say Ursula, an engineer in one of the development teams, needs to add a dead letter queue to one of our AWS SQS queues:
1. She locates the relevant Terraform file in our Terraform monorepo, makes the change in the file in the sandbox directory in a new branch, and opens a pull request.
2. The repo CI/CD pipeline generates a terraform plan. The plan is posted as a comment to PR and persisted in S3 for later use. The PR is assigned to the owning team, and its members are notified.
3. They go over the plan and the changed files, possibly look at the Jira ticket attached to the branch and approve the PR.
4. Ursula merges the PR, another CI/CD pipeline runs, applies the previously persisted plan and notifies her after completion.
5. After the merge, a 2nd PR is automatically opened, promoting the change to the production folder. After approval from the owning team and assuming the sandbox change had the desired effect, she merges the 2nd PR and the pipeline applies the changes as before.
Now let’s break down what was described above.
Code Structure
Workspaces
Did you say Monorepo?
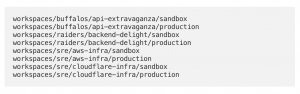
Small Terraform workspaces run faster, avoid locking and vendor API rate limit issues, and are generally easier to maintain. This is why we have just over 100 small terraform workspaces. Each is named after the service that owns the cloud objects and the environment it is deployed on.
Infrastructure-related objects that cross service ownership borders like AWS VPCs are usually owned by the SRE team, where they are grouped under workspaces with descriptive names (aws-infra). All those workspaces are nested under the engineering team directory, helping navigation and usage of GitHub CODEOWNERS files.

So:
In the future, we plan to move the service-owned workspaces to their respective code repo, but even then, we’ll have enough infrastructure workspaces to warrant the extra overhead of still having a monorepo (as opposed to a repo per workspace).
Environment Dichotomy
You probably noticed that the code is duplicated for each environment, causing a severe itching sensation to anyone who prides themselves in writing DRY code. But there is a reason for this choice. While we call the Terraform files code, they are first and foremost a declarative, current representation of our cloud resources and as such are immediately applied to the cloud API on every change to the main branch(GitOps!). To allow control over the timing of promotion to each environment (like production) a copy for each environment is required and while using git branches for managing those copies and synchronization is possible, it breaks our current, simple, well-understood branching model.
This approach can cause issues with drift across environments, human error and extra toil while promoting changes but I’ll explain how we address and mitigate those issues when I describe the pipeline.
To allow meaningful testing, Sandbox and Production and other environments are structurally and logically identical but of course some differences are unavoidable, usually stuff that relates to scale like Kubernetes cluster max size, or references to some globally unique objects like world accessible fully qualified URLs and s3 buckets names. Those changes are reflected in global and environment specific .tfvar override files (global.tfvar + sandbox.tfvar/production.tfvar).
Where unavoidable, we use Terraform’s less-than-pretty conditionals (based on boolean values in the tfvars). While it’s tempting to just use those mechanisms for referencing multiple environments in a single code directory, control over the timing of a change in each environment was not something we wanted to forsake. With the setup described above, we avoid cases where an error in some conditional expressions or a tfvar file causes an unexpected change in the production environment.
The Pipeline
Terraform work
Why even use a pipeline? In the good old days we just ran Terraform for our workstations and everything went fine!
Maybe, depending on the size of the team, the velocity of changes, and how strictly everyone follows policy, you may or may not have encountered the infamous office (slack) shoutout “Who pushed before applying?” or the more dangerous “Who applied without pushing?” But even if you haven’t encountered this for yourself, an IaC CD pipeline improves security by negating the need to keep powerful API tokens on workstations, or even give elevated permissions to users who need to manipulate cloud resources. It forces peer review, ensures tool version parity, and significantly reduces toil on every change and initial workstation setup.
On every PR open and update, we check Terraform formatting and generate a plan, we display the plan output as a comment in the PR and save the plan file to s3 to use when the PR is merged.

On PR merge, we fetch the last plan in PR and apply it. This ensures that only API actions that were reviewed and approved are run, regardless of how the code looks after the merge. If another action has changed the state so the plan is stale, Terraform will refuse to run the plan and will fail the pipeline. This was a conscious choice, erring on the side of caution, and while creating some extra work (rerunning the pipeline), this is extremely rare because of the small workspaces.
There’s no extra manual approval process – merging to the main branch is the approval. This means the git code always represents the status of the cloud resources.
Promotion of changes across environments
If we stopped here, every change would have applied to each environment folder manually and separately, introducing copy errors, drift, and general resentment toward the person who created the flow. This is how we avoid these scenarios.
Engineers are expected to directly interact only with files on the sandbox workspaces. After those changes are merged we automagically open a 2nd PR for syncing the matching production workspace. And after another approval by the relevant team and assuming the sandbox change was successful and generally met the expectation, the engineers just need to merge the 2nd PR to apply the change to production.
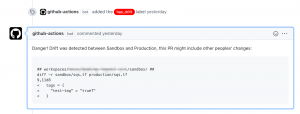
If two PRs are run concurrently, or someone elected not to promote their changes to production but kept them in sandbox, the newer, automated promotion PR will also include those changes. While this reduces drift it adds risk and uncertainty, so in those cases we automatically add a warning comment and (a red!) label to both PRs, the original and the 2nd automated one.
Summary
So this is what we achieved:
- The user interacts with files and Git(and Github). No tooling, no tokens, no extra UI.
- Every change is peer-reviewed.
- Under normal conditions, the files in the main branch always reflect the state of the cloud API.
- The user has complete control over the promotion of changes to Production.
- The system reduces drift between environments by design.
I hope you found this useful, we are considering using a similar approach with our Kubernetes manifests, stay tuned for a follow-up article.
Anticipated Questions
Content that didn’t fit in the main body of the post but might help the reader understand some of our choices.
- Why not CDK, Pulumi, Crossplane? Terraform DSL is very readable, while its lack of proper control structures and variable scoping is sometimes infuriating, it forces us to write simple, explicit code that is very easy to understand and conforms to the GitOps guidelines. Plumi/CDK both seem very nice but would require a lot of effort to keep this simple and have uniform code across all the authors in the company.
Crossplane also looks very interesting, but currently lacks provider support, I also find it hard to give up the Terraform plan feature, even with Crossplane extra safeguards.
We also ruled out any vendor specific solution like AWS Service Operator. - Why not Terraform Enterprise, Atlantis? – because we need all the engineers to interact with Terraform pricing was a big concern, we also prefer not to add another tool with its own UI. The other big reason that both Atlantis and TF enterprise doesn’t exactly match our “On merge to master, apply exactly what was approved in the PR” approach
- What CI/CD system do you use? – We currently use both CircleCI and Github Actions(!). CircleCI is our current company-wide CI solution but we use Github Actions in places we needed proper monorepo support and easy interaction with PRs. At some point, we’ll want to consolidate back to a single vendor. We’re waiting for CircleCI to release some relevant features to make a decision.
- Can you share the complete CI/CD code or a reference repo? Because of the dual CI/CD systems I mentioned above, it’s not a pretty sight. But if there’s demand, we could probably get something somewhat presentable up. Let us know in the comments!
- Aren’t you exposing yourself to secret leak issues? - well, yes. Terraform runs with extensive cloud IAM permissions to allow it to manipulate objects in our cloud providers. The developers have much more restrictive access, but with our current setup, a malicious engineer can make changes to the pipeline in a PR, (before it gets peer-reviewed!) and get the token or just use it for something other than generating/applying a Terraform plan. This is mitigated by auditing and alerting on changes to our cloud API and using multiple monorepos with different pipeline permissions and restricting their access based on team membership.
Don’t forget to keep an eye on our Forto Career pages — we are expanding, and we would love you to join us.